[Goal]
같은 공간이지만 view point가 많이 다른 2개의 이미지에 대한 robust feature matching을 할 수 있다.
[LightGlue Github page] [Advantages]
GPU 소모가 많이 안들면서 feature matching 이 잘되는 model
Viewpoint가 많이 달라도 robust하게 feature matching 이 잘되는 model
[Dependencies] python 3.8 pytorch 2.0.1 cuda 11.7 torchvision 0.15.2 einops 0.6.1 kornia 0.7.0 xformers 0.0.21 opencv-python matplotlib [Model Configuration]
SuperPoint (feature extraction part)
def __init__(self, **conf):
super().__init__()
self.conf = {**self.default_conf, **conf}
self.relu = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
c1, c2, c3, c4, c5 = 64, 64, 128, 128, 256
self.conv1a = nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)
self.conv1b = nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)
self.conv2a = nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)
self.conv2b = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)
self.conv3a = nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)
self.conv3b = nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)
self.conv4a = nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)
self.conv4b = nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)
self.convPa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convPb = nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)
self.convDa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convDb = nn.Conv2d(
c5, self.conf['descriptor_dim'],
kernel_size=1, stride=1, padding=0)
url = "https://github.com/cvg/LightGlue/releases/download/v0.1_arxiv/superpoint_v1.pth"
self.load_state_dict(torch.hub.load_state_dict_from_url(url))
mk = self.conf['max_num_keypoints']
if mk is not None and mk <= 0:
raise ValueError('max_num_keypoints must be positive or None')
def forward(self, data: dict) -> dict:
""" Compute keypoints, scores, descriptors for image """
for key in self.required_data_keys:
assert key in data, f'Missing key {key} in data'
image = data['image']
if image.shape[1] == 3: # RGB
scale = image.new_tensor([0.299, 0.587, 0.114]).view(1, 3, 1, 1)
image = (image*scale).sum(1, keepdim=True)
# Shared Encoder
x = self.relu(self.conv1a(image))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x))
# Compute the dense keypoint scores
cPa = self.relu(self.convPa(x))
scores = self.convPb(cPa)
scores = torch.nn.functional.softmax(scores, 1)[:, :-1]
b, _, h, w = scores.shape
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8)
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8)
scores = simple_nms(scores, self.conf['nms_radius'])
# Discard keypoints near the image borders
if self.conf['remove_borders']:
pad = self.conf['remove_borders']
scores[:, :pad] = -1
scores[:, :, :pad] = -1
scores[:, -pad:] = -1
scores[:, :, -pad:] = -1
# Extract keypoints
best_kp = torch.where(scores > self.conf['detection_threshold'])
scores = scores[best_kp]
# Separate into batches
keypoints = [torch.stack(best_kp[1:3], dim=-1)[best_kp[0] == i]
for i in range(b)]
scores = [scores[best_kp[0] == i] for i in range(b)]
# Keep the k keypoints with highest score
if self.conf['max_num_keypoints'] is not None:
keypoints, scores = list(zip(*[
top_k_keypoints(k, s, self.conf['max_num_keypoints'])
for k, s in zip(keypoints, scores)]))
# Convert (h, w) to (x, y)
keypoints = [torch.flip(k, [1]).float() for k in keypoints]
# Compute the dense descriptors
cDa = self.relu(self.convDa(x))
descriptors = self.convDb(cDa)
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1)
# Extract descriptors
descriptors = [sample_descriptors(k[None], d[None], 8)[0]
for k, d in zip(keypoints, descriptors)]
return {
'keypoints': torch.stack(keypoints, 0),
'keypoint_scores': torch.stack(scores, 0),
'descriptors': torch.stack(descriptors, 0).transpose(-1, -2).contiguous(),
}
DISK (feature extraction part)
LightGlue (feature matching part)
def __init__(self, features='superpoint', **conf) -> None:
super().__init__()
self.conf = {**self.default_conf, **conf}
if features is not None:
assert (features in list(self.features.keys()))
self.conf['weights'], self.conf['input_dim'] = \
self.features[features]
self.conf = conf = SimpleNamespace(**self.conf)
if conf.input_dim != conf.descriptor_dim:
self.input_proj = nn.Linear(
conf.input_dim, conf.descriptor_dim, bias=True)
else:
self.input_proj = nn.Identity()
head_dim = conf.descriptor_dim // conf.num_heads
self.posenc = LearnableFourierPositionalEncoding(2, head_dim, head_dim)
h, n, d = conf.num_heads, conf.n_layers, conf.descriptor_dim
self.transformers = nn.ModuleList(
[TransformerLayer(d, h, conf.flash) for _ in range(n)]
)
self.log_assignment = nn.ModuleList(
[MatchAssignment(d) for _ in range(n)])
self.token_confidence = nn.ModuleList([
TokenConfidence(d) for _ in range(n-1)])
self.register_buffer('confidence_thresholds', torch.Tensor([
self.confidence_threshold(i) for i in range(self.conf.n_layers)]))
state_dict = None
if features is not None:
fname = f'{conf.weights}_{self.version}.pth'.replace('.', '-')
state_dict = torch.hub.load_state_dict_from_url(
self.url.format(self.version, features), file_name=fname)
self.load_state_dict(state_dict, strict=False)
elif conf.weights is not None:
path = Path(__file__).parent
path = path / 'weights/{}.pth'.format(self.conf.weights)
state_dict = torch.load(str(path), map_location='cpu')
if state_dict:
# rename old state dict entries
for i in range(self.conf.n_layers):
pattern = f'self_attn.{i}', f'transformers.{i}.self_attn'
state_dict = {k.replace(*pattern): v for k, v in state_dict.items()}
pattern = f'cross_attn.{i}', f'transformers.{i}.cross_attn'
state_dict = {k.replace(*pattern): v for k, v in state_dict.items()}
self.load_state_dict(state_dict, strict=False)
# static lengths LightGlue is compiled for (only used with torch.compile)
self.static_lengths = None[Get Pre-trained Model]
자동적으로 URL을 통해서 다운 받게 coding 되어 있지만 수동적으로 해당 모델을 다운 받아서 사용할 수 있다.
[Basic Code] from lightglue import LightGlue, SuperPoint, DISK
from lightglue.utils import load_image, rbd
import pdb
query_path = "~/query.png"
cand_path = "~/cand.png"
# SuperPoint+LightGlue
extractor = SuperPoint(max_num_keypoints=2048).eval().cuda() # load the extractor
matcher = LightGlue(features='superpoint').eval().cuda() # load the matcher
# or DISK+LightGlue
extractor = DISK(max_num_keypoints=2048).eval().cuda() # load the extractor
matcher = LightGlue(features='disk').eval().cuda() # load the matcher
# load each image as a torch.Tensor on GPU with shape (3,H,W), normalized in [0,1]
image0 = load_image(query_path).cuda()
image1 = load_image(cand_path).cuda()
# extract local features
feats0 = extractor.extract(image0) # auto-resize the image, disable with resize=None
feats1 = extractor.extract(image1)
# match the features
matches01 = matcher({'image0': feats0, 'image1': feats1})
feats0, feats1, matches01 = [rbd(x) for x in [feats0, feats1, matches01]] # remove batch dimension
matches = matches01['matches'] # indices with shape (K,2)
points0 = feats0['keypoints'][matches[..., 0]] # coordinates in image #0, shape (K,2)
points1 = feats1['keypoints'][matches[..., 1]] # coordinates in image #1, shape (K,2)
# conversion to (H, W, 3) for torch.Tensor
plt_img1 = [img.permute(1, 2, 0).cpu().numpy() if (isinstance(img, torch.Tensor) and img.dim() == 3) else img for img in image0]
plt_img2 = [img.permute(1, 2, 0).cpu().numpy() if (isinstance(img, torch.Tensor) and img.dim() == 3) else img for img in image1]
# convert torch.Tensor to numpy
np_img1 = np.zeros(shape=(480, 640, 3), dtype=float)
np_img2 = np.zeros(shape=(480, 640, 3), dtype=float)
for i in range(0, 3):
np_img1[:, :, i] = plt_img1[i].cpu()
np_img2[:, :, i] = plt_img2[i].cpu()
# Plot keypoint in each images
plt.scatter(points0[:,0].cpu(), points0[:,1].cpu(), c='green', s=5)
plt.imshow(np_img1)
plt.show()
plt.scatter(points1[:,0].cpu(), points1[:,1].cpu(), c='green', s=5)
plt.imshow(np_img2)
plt.show()[Experiments]
View point가 다른 challenging 한 이미지 pair 3쌍을 준비
Query Image Candidate Image
Test Pair 2 (Challenging !
Query Image Candidate Image
Query Image Candidate Image
[Result]
LightGlue에서 주어진 pre-trained model을 적용하여 해당 결과 plot (본 데이터셋으로 추가 train 시키지 않음)
[Case 1: SuperPoint + LightGlue]
주어진 desktop 환경은 NVIDIA RTX 3060 이 탑재되어 있고 SuperPoint + LightGlue를 돌리면 약 2.5GB 정도의 GPU memory 소모
# Debug
feats0 type: <class 'dict'> -> "keypoints" "keypoint_scores" "descriptors" "image_size"
feats0["keypoints"] type: <class 'torch.Tensor'> & size: torch.Size([809, 2])
feats0["keypoint_scores"] type: <class 'torch.Tensor'> & size: torch.Size([809])
feats0["descriptors"] type: <class 'torch.Tensor'> & size: torch.Size([809, 256])
feats0["image_size"] type: <class 'torch.Tensor'> & size: torch.Size([2])
feats1 type: <class 'dict'> -> "keypoints" "keypoint_scores" "descriptors" "image_size"
feats1["keypoints"] type: <class 'torch.Tensor'> & size: torch.Size([1120, 2])
feats1["keypoint_scores"] type: <class 'torch.Tensor'> & size: torch.Size([1120])
feats1["descriptors"] type: <class 'torch.Tensor'> & size: torch.Size([1120, 256])
feats1["image_size"] type: <class 'torch.Tensor'> & size: torch.Size([2])
matches01 type: <class 'dict'> -> "matches0" "matches1" "matching_scores0" "matching_scores1" "matches" "scores" "prune0" "prune1"
matches01["matches0"] type: <class 'torch.Tensor'> & size: torch.Size([809])
matches01["matches1"] type: <class 'torch.Tensor'> & size: torch.Size([1120])
matches01["matching_scores0"] type: <class 'torch.Tensor'> & size: torch.Size([809])
matches01["matching_scores1"] type: <class 'torch.Tensor'> & size: torch.Size([1120])
matches01["matches"] type: <class 'torch.Tensor'> & size: torch.Size([94, 2])
matches01["scores"] type: <class 'torch.Tensor'> & size: torch.Size([94])
matches01["prune0"] type: <class 'torch.Tensor'> & size: torch.Size([809])
matches01["prune1"] type: <class 'torch.Tensor'> & size: torch.Size([1120])
points0 type: <class 'torch.Tensor'> & size: torch.Size([94, 2])
points1 type: <class 'torch.Tensor'> & size: torch.Size([94, 2])
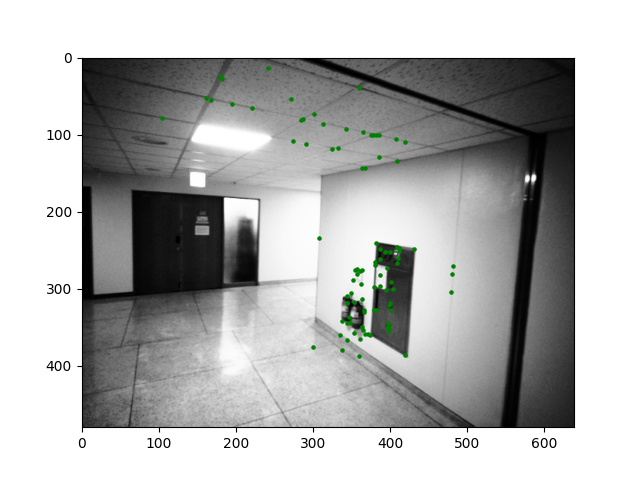
Feature Matching Result (inlier = 94 )
[Case 2: DISK + LightGlue]
주어진 desktop 환경은 NVIDIA RTX 3060 이 탑재되어 있고 DISK + LightGlue를 돌리면 약 4.5GB 정도의 GPU memory 소모
##### max_num_keypoints=2048 으로 설정해두어서 DISK로 하는 경우에는 모두 feature가 추출되는 것을 볼 수 있음 #####
# Debug
feats0 type: <class 'dict'> -> "keypoints" "keypoint_scores" "descriptors" "image_size"
feats0["keypoints"] type: <class 'torch.Tensor'> & size: torch.Size([2048, 2])
feats0["keypoint_scores"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
feats0["descriptors"] type: <class 'torch.Tensor'> & size: torch.Size([2048, 128])
feats0["image_size"] type: <class 'torch.Tensor'> & size: torch.Size([2])
feats1 type: <class 'dict'> -> "keypoints" "keypoint_scores" "descriptors" "image_size"
feats1["keypoints"] type: <class 'torch.Tensor'> & size: torch.Size([2048, 2])
feats1["keypoint_scores"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
feats1["descriptors"] type: <class 'torch.Tensor'> & size: torch.Size([2048, 128])
feats1["image_size"] type: <class 'torch.Tensor'> & size: torch.Size([2])
matches01 type: <class 'dict'> -> "matches0" "matches1" "matching_scores0" "matching_scores1" "matches" "scores" "prune0" "prune1"
matches01["matches0"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
matches01["matches1"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
matches01["matching_scores0"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
matches01["matching_scores1"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
matches01["matches"] type: <class 'torch.Tensor'> & size: torch.Size([57, 2])
matches01["scores"] type: <class 'torch.Tensor'> & size: torch.Size([57])
matches01["prune0"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
matches01["prune1"] type: <class 'torch.Tensor'> & size: torch.Size([2048])
points0 type: <class 'torch.Tensor'> & size: torch.Size([57, 2])
points1 type: <class 'torch.Tensor'> & size: torch.Size([57, 2])
[CASE 1] max_num_keypoints = 2048
[CASE 2] max_num_keypoints = 4096
[CASE 3] max_num_keypoints = 8192 (이 경우는 7GB 정도 소모됨…)
[CASE 4] max_num_keypoints = 15000 (이 경우는 7GB 정도 소모됨…)
[CASE 5] max_num_keypoints = 20000 (이 경우는 7GB 정도 소모됨…)
[CASE 1] max_num_keypoints = 2048 & matching pair = 57
[CASE 2] max_num_keypoints = 4096 & matching pair = 74
[CASE 3] max_num_keypoints = 8192 & matching pair = 128 (이 경우는 7GB 정도 소모됨…)
[CASE 4] max_num_keypoints = 15000 & matching pair = 138 (이 경우는 7GB 정도 소모됨…)
[CASE 5] max_num_keypoints = 20000 & matching pair = 139 (이 경우는 7GB 정도 소모됨…)
[Ablation Study]
# of inliers: 94 # of inliers: 112 # of inliers: 49
DISK + LightGlue (max_num_keypoints = 2048)
# of inliers: 57 # of inliers: 19 # of inliers: 74
DISK + LightGlue (max_num_keypoints = 4096)
# of inliers: 74 # of inliers: 15 # of inliers: 90
DISK + LightGlue (max_num_keypoints = 8192)
# of inliers: 128 # of inliers: 13 # of inliers: 24
DISK + LightGlue (max_num_keypoints = 15000)
# of inliers: 138 # of inliers: 18 # of inliers: 12
DISK + LightGlue (max_num_keypoints = 20000)
# of inliers: 139 # of inliers: 18 # of inliers: 12